Search engines serve as your online gateway. They analyze large amounts of information on a website and decide how effectively it answers a given inquiry.
But, with so much information to sort through, how do search engines actually work?
Your material must first be made available to search engines in order to appear in search results. It is perhaps the most crucial aspect of SEO: If your site cannot be found and read, you will never appear in the SERPs.
If you are a developer, a web designer, a designer, a business owner, a marketing or sales professional, any sort of website owner, or are simply considering developing a personal blog or website for your company, you will need to understand how search engines work in order to stay ahead.
You will also need to know how search engines work in order to stay ahead of inevitable search engine algorithm changes, so unfortunately, this is the knowledge that you will need to keep developing in the longer term.
Understanding how search works will help you develop a website that search engines can easily and clearly understand, which has a variety of additional benefits.
This is the first step you must do before beginning any Search Engine Optimization or Search Engine Marketing projects.
Search engines use complex algorithms to determine the quality and relevance of every page in order to discover, categorize, and rank the billions of websites that comprise the internet.
It is a complicated process requiring a large quantity of data, all of which must be presented in an easy-to-understand format for end users so they can actually use the resulting search results.
Search engines analyze all of this data by examining a variety of ranking variables depending on a user’s query. This includes relevance to the inquiry a user typed in, content quality, site performance, metadata, and other factors.
Each data piece is integrated into the complex algorithms that make search engines work, all to assist search engines in determining the overall quality of a page. The website is then rated and given to the user in their search results depending on the search engines’ calculations.
Let’s take a look at the basics of how search engines work. We will cover search engine algorithms for Google and other search engines, as well as mysterious-sounding terms like search engine crawlers, search engine spiders, search engine bots, and the all-important concepts of crawling, indexing, and ranking.
So, if you have ever been curious about understanding how search engines actually work, read on below for the answers!
How Does a Search Engine Work?
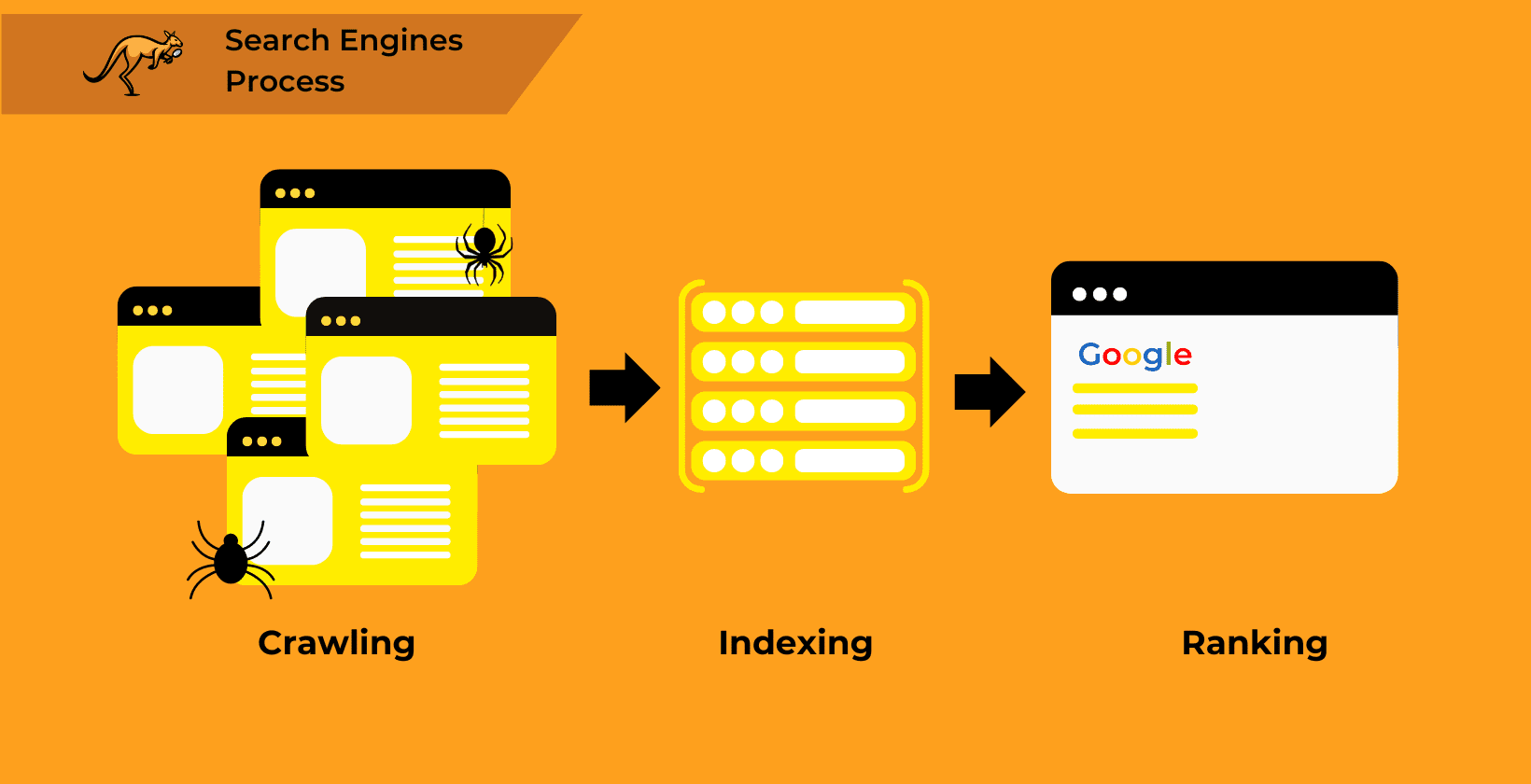
Search engines, sophisticated as they are, initiate their functionality through a structured preparation sequence before you even key in a query.
This sequence ensures that the “Search” button yields accurate and high-quality answers. It comprises three distinct phases: discovering the web’s content, organizing it logically, and prioritizing it based on perceived relevance and utility.
In SEO terms, these phases are known as crawling, indexing, and ranking, fundamental operations not just for Google but for all search engines. While crawling and indexing lay the groundwork by identifying and cataloging web content, ranking intricately sorts this content, guided by complex algorithms.
These algorithms, specific to platforms like Google’s RankBrain or Bing’s Space Partition Tree And Graph (SPTAG), critically assess a website’s potential value to a user. Each search engine employs unique algorithms and ranking factors, meaning a top position in one engine’s results doesn’t ensure a similar rank across others.
Preferences vary: some search engines weigh content quality more heavily, others user experience or the efficacy of link-building strategies. Navigating these preferences is key to achieving visibility in search engine results pages (SERPs).
As we delve into the intricacies of how these engines operate, starting with the very foundation of the web search process opens a window into the critical role of crawling in understanding and navigating the vastness of the internet.
What is Search Engine Crawling?
Crawling is the process by which search engine web crawlers (also known as bots or spiders) explore and download a page in order to locate other sites based on the links hosted on that web page. Crawling (and indexing) are the foundations of how any search engine works.
Pages that are already known to the search engine are crawled on a regular basis to see whether there have been any changes to the page’s content since the previous time it was crawled.
If a search engine finds changes to a page after crawling it, it will update its index to reflect the changes.
To identify and access online sites, search engines employ their own web crawlers.
All commercial search engine crawlers start crawling a website by downloading the robots.txt file found on the site, which provides rules governing which pages search engines should and should not crawl on the domain.
The robots.txt file can additionally include sitemap information, which is a list of URLs that the site wishes a search engine crawler to explore.
To determine how frequently a website should be scanned and how many pages on a site should be indexed, search engine crawlers employ a variety of algorithms and criteria. A page that changes regularly, for example, may be crawled more often than one that is not modified very often.
Search engines will generally try to crawl and index every URL they come across. If the discovered URLs refer to a non-text file format, such as an image, video, or audio file, search engines will often be unable to access the file’s content other than the accompanying filename and metadata.
Despite the fact that a search engine can only extract a limited amount of information from non-text file formats, they are still able to be indexed, ranked in search results, and get traffic.
Crawlers uncover new pages by re-crawling previously visited pages and then extracting links to other pages to find new URLs. These newly discovered URLs are added to the crawl queue and will be downloaded later.
Crawling search engines may locate any publicly available webpage on the internet that is connected from at least one other page by following links. This is the main purpose of the crawling process.
Sitemaps can also be crawled by search engines to locate new pages. Sitemaps are collections of URLs that may be generated by a website to provide search engines with a list of pages to crawl.
These can assist search engines in discovering material that is hidden deep inside a website. This is why it is worth having an XML sitemap for your web content.
It will reduce crawl errors and make it as easy as possible for your important pages to get indexed on the search engines as fast as possible.
Essentially, crawlers are computer program bots that move from one website to other websites along links, like a spider crawling along a thread of its web.
It starts with already indexed pages and then moves to external websites, adding any new page it finds to its huge database of web pages. Search engines send these bots out constantly in order to keep Google search results (and other results in the search engine market) from becoming outdated.
Understanding Crawl Budgets
The crawl budget, a crucial metric, is essentially the product of crawl rate and demand, defining the number of URLs from a website that a search engine can scan within a certain time frame.
This budget is capped to prevent overloading a website’s server, which could hinder the site’s functionality and negatively impact the visitor experience.
Each server, depending on whether it is a shared or dedicated server, has a limit on how many connections it can handle, directly influencing the crawl budget allocated to the websites it hosts.
For instance, websites on dedicated servers typically receive a larger crawl budget due to their ability to manage higher traffic and maintain fast response times more effectively. Understanding and optimizing this budget can empower you to enhance your website’s performance and user experience.
Moreover, the allocation of a crawl budget is not solely determined by server capabilities but also by the quality of the website’s content. Even if a site is technically optimized for high-speed responses, a search engine may limit its resource investment if the content is not considered sufficiently valuable.
This underscores the necessity of optimizing server response times and content relevance to maximize a website’s crawl budget. Investing in high-quality content can significantly boost your website’s crawl budget, leading to improved search engine visibility and user engagement.
Efficient crawling is not the only aspect to consider in website optimization. We must also understand how the gathered information is organized and utilized.
This leads us to the next crucial component: indexing. Indexing is a cornerstone of website optimization, as it shapes how search engines interpret and rank your content. Mastering this aspect can lead to a significant boost in your website’s visibility and organic traffic.
What is Search Engine Indexing?
After a search engine completes its crawl of a webpage, it transitions to a crucial phase called indexing.
In this process, the search engine organizes website information into a structured format to instantly deliver relevant, high-quality search results. The method involves web crawlers identifying and collecting necessary data, which is then systematically filed for efficient retrieval.
Indexing employs an inverted index, a database that catalogs text elements and their document locations. This system allows for quick data retrieval without needing real-time page crawling, which would significantly slow down the search process.
By using tokenization, search engines reduce words to their base forms, optimizing the storage and retrieval of information.
In addition to creating an inverted index, search engines may store a compressed text-only version of a document, including all HTML and metadata.
This cached document represents the most recent snapshot of the page as seen by the search engine.
For instance, Google allows users to view a page’s cached version through a specific URL link, enhancing access to outdated or no longer available content. Bing offers a similar feature, though it lacks the specific search operator that Google provides.
As we understand indexing’s efficiency, we edge closer to seeing how it sets the stage for the next sophisticated step: determining how all this indexed information is ranked to effectively meet user queries.
How do Search Engine Rankings Work?
When a user performs a search and inputs a query, the third and last stage is for search engines to pick which sites to show in the SERPS and in what order.
There are many ranking factors, and each search algorithm prioritizes them differently, but the most important to understand is the Google search algorithm.
This is accomplished by employing search engine ranking algorithms. In their most basic form, these algorithms are pieces of software with a set of rules that assess what the user is looking for and determine what information to deliver as a result of the query.
They aim to provide relevant results to each user query, which is a complex process. These rules and choices that the search engine algorithm uses to identify relevant results are based on the information included in the search engine’s index.
Search engine ranking algorithms have changed and become quite intimidatingly complicated over time.
It used to be that matching the user’s query with the title of the page was pretty much all the algorithm did, but that is no longer the case.
Any modern search engine algorithm will use a huge number of ranking factors to find and display relevant results, and all search engines work slightly differently from each other.
Before making a conclusion, Google’s ranking system considers many factors: more than 255 criteria, the details of which are unknown to everyone outside the Google team.
Things have changed dramatically, and now machine learning and computer programs are in charge of making judgments based on a variety of characteristics that extend beyond the content of a web page.
Insights into Search Engine Algorithms
The first stage of how search engine algorithms work is for the search engines to determine what type of information the user is actually searching for. To do so, they break down the user’s query (specifically the search phrases) into a number of useful keywords.
A keyword is a term with a defined meaning and function. Machine learning has enabled search engine algorithms to connect relevant terms together, allowing them to deduce a portion of your purpose from the word you use. Anchor text, a crucial component of hyperlinking, serves as a pivotal cue for search engine algorithms, helping them deduce the relevance and purpose behind linked content.
For example, if you include the word “buy” in your query, they will limit the results to shopping websites.
They are also capable of interpreting spelling errors, comprehending plurals, and extracting the intended meaning of a query from natural language, including spoken language for Voice Search users.
The second step in how the algorithms for search engines work is to search their index for sites that can provide the best response to a particular query.
This is a critical stage in the process for both the search engines themselves and the website owners whose content may be returned in the search engine results pages.
Search engines must produce the best possible results in the shortest amount of time in order to keep their users satisfied, while website owners want their websites to be picked up in order to receive traffic and views.
This is also the point at which making use of effective search engine optimisation strategies could have an effect on the algorithms’ decisions. You can take advantage of how search engines work to push your content further up the search results.
To receive visitors from search engines, your website must be toward the top of the first page of results. It has been well established that the majority of users (both on desktop and mobile) click on one of the top five results. Appearing on the second or third page of search results will attract almost no visitors to your page.
Traffic is only one of the benefits of SEO; if you reach the top rankings for keywords that are relevant to your organization, the other benefits are numerous.
Understanding how search engines function can help you improve your website’s ranks and traffic. The next part of the rankings system is PageRank.
The Role of PageRank in Search Algorithms
PageRank, named for Google co-founder Larry Page, reflects a metric distinct from webpage rankings despite the name’s implication.
It operates on a system of values derived from the volume and quality of inbound links to assess a page’s importance relative to others on the web.
Each link contributes to this value, acting as a vote of confidence influencing the receiving page’s standing in search results. Although PageRank once featured in public Google metrics, it now functions as one of many factors within a broader ranking algorithm.
It is no longer visible to the public. Other search engines implement similar systems to gauge link equity. While some SEO tools offer estimations of PageRank, their accuracy varies.
The dissemination of PageRank through links, or “link juice,” involves each outbound link from a page distributing a portion of its value to linked pages, unless marked with a “nofollow” attribute, which stops this transfer.
As pages accumulate links, they build their own PageRank, enhancing their potential to rank well.
To enhance your site’s visibility and ranking in this complex web of connections, understanding and facilitating how search engines crawl your site is crucial.
How to Help Search Engines Crawl Your Site?
Understanding how Google interacts with your site is crucial for owners, and Google Search Console is a key resource. It reveals the performance of individual pages or blog posts in search rankings for relevant queries.
Through intuitive visualizations like the knowledge graph, observing the impact of ranking factors on your site traffic becomes straightforward.
For those who have navigated Google Search Console, it may come to light that certain key pages are missing from the index or less relevant pages are indexed by mistake. There are strategies you can employ to better direct Googlebot, enhancing control over your content’s indexing.
Optimizing the visibility of essential pages while shielding others—like outdated URLs, duplicate filter parameters, or pages under construction—is crucial. Using robots.txt files helps specify which areas of your site should be avoided by search engines and the frequency of their crawls.
While effective for most, it’s worth noting that not all web robots respect these directives; some malicious bots use robots.txt to locate sensitive information.
Despite the risks, restricting access via robots.txt to private sections, like login and admin areas, seems practical. Yet, such actions can inadvertently make these pages more accessible to malicious entities.
As we explore the ways we can influence how search engines like Google navigate our sites, it’s interesting to consider how these same engines adapt their responses to individual users. How do personalized results in search engines work, and what can we learn from these adaptations?
How do Personalized Results in Search Engines Work?
When you search for information, your results generally mirror those of others using the same query.
However, personalization factors such as your online behavior can influence the prioritization of certain pages. For example, Google adjusts search engine results pages (SERP) based on factors like user location.
This local customization ensures that offerings near you are more likely to appear if you search for services or products. This local focus is especially pertinent for service-based businesses like restaurants, which benefit from reaching customers nearby.
Additionally, language plays a key role in how search engines filter results. A search conducted in a language other than English prompts search engines to prioritize content in that language.
If available, they also prefer websites with translations, aligning more closely with the user’s language preference.
Search engines further personalize by analyzing your search history and online behavior. Frequent searches for specific types of content, such as news, can lead to those categories being highlighted more often in your results.
Revisiting websites also affects outcomes, with previously visited sites more likely to resurface, often accompanied by information on when you last accessed them.
As we explore these personalized aspects of search engine operations, we set the stage for discussing the broader implications and mechanics in our final overview. We combine these elements to highlight the sophisticated nature of modern search engines.
Final Overview: Understanding the Complete Search Engine Process
Search engines have evolved into extremely complicated computer programs with a number of algorithms and bots incorporated into their workings. Their user interface may be basic, but the way they function and make judgments is anything but.
Crawling and indexing are the first steps in the process of how search engines work. During this phase, search engine crawler bots collect as much information as possible for all publicly accessible websites on the internet.
Search engines work to find, analyze, sort, and store this information in a way that search engine algorithms can utilize to make a judgment and offer the best results to the user to match their search queries.
They have a massive quantity of data to handle, and the process of search engine crawling, indexing, and ranking is totally automated by search engine bots.
Human interaction is only needed in the process of developing the rules that will be employed by the various types of search engine algorithm, although even this stage is being increasingly replaced by computers using artificial intelligence.
However, the implementation of these rules and the continuous refinement of search algorithms heavily rely on human input to ensure relevance and effectiveness, especially in the dynamic landscape of business online with ecommerce.
Your role as a webmaster is to make crawling and indexing easy for them by designing websites with a clear and straightforward layout so that when search engines discover your site, they can understand it easily and grasp the content of all the pages on your website.
Once they can “read” your website without any problems, you must ensure that you provide them with the correct signals to assist their search ranking algorithms in selecting your website when a user types a relevant query.




